- AI Sparkup
- Posts
- 클래식 RAG가 놓친 것, 에이전틱 루프가 바꾸는 것 🔄
클래식 RAG가 놓친 것, 에이전틱 루프가 바꾸는 것 🔄
PLUS: 코딩 성공률 28%→96% 끌어올린 Agent Skill, Harvard 교수가 확인한 Claude의 박사 2년차 실력, Karpathy가 그은 AI 자율 연구의 경계선, AI 생산성 혁명의 불편한 데이터
AI Sparkup ⚡
April 02, 2026 • Estimated Reading Time: 1 minute
RAG 시스템이 틀린 답을 내놓을 때, 시스템은 대개 아무것도 모릅니다. 틀렸다는 사실도, 왜 틀렸는지도요.
Towards Data Science에 기고된 분석이 클래식 RAG의 구조적 한계를 짚었습니다. 단방향 파이프라인은 검색이 어긋나도 되돌아갈 방법이 없고, 에이전틱 RAG는 이 흐름을 루프로 바꿔 스스로 검증하고 다시 시도합니다. 단, 루프가 만능은 아닙니다. 비용이 분포가 되고, 수렴하지 못하는 새로운 실패 모드가 생기죠.
Today's AI Spark⚡:
클래식 RAG가 조용히 실패하는 구조, 에이전틱 RAG는 뭘 다르게 하나
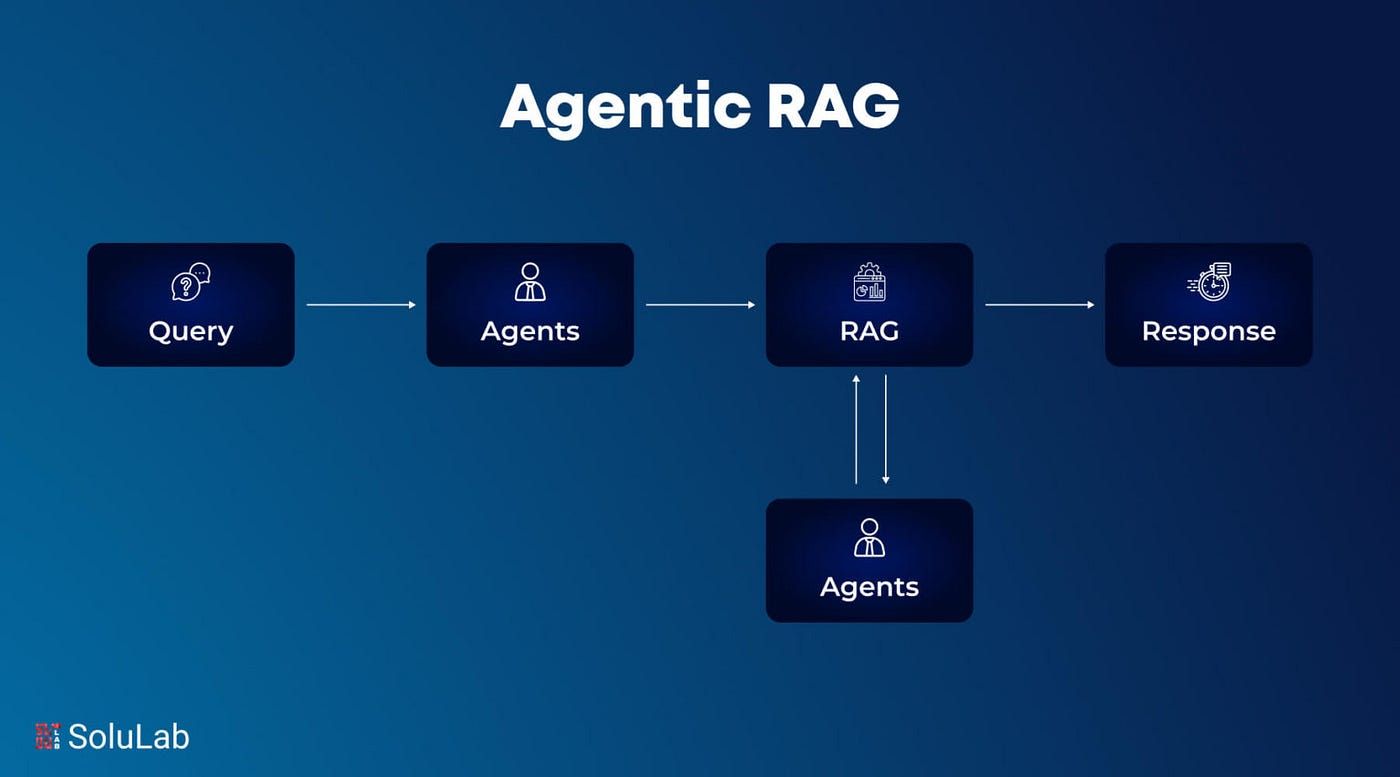
사진 출처: Agentic RAG: What is It, Its Types, Applications And Implementation | by SoluLab | Artificial Intelligence in Plain English
클래식 RAG는 질문을 받아 벡터 검색으로 청크를 찾고, LLM에 넘겨 답을 만드는 단방향 파이프라인입니다. 문제는 어느 단계가 어긋나도 뒤로 돌아갈 방법이 없다는 것인데요. 검색 엔지니어 Doug Turnbull이 든 예시가 인상적입니다 — 파리 여행 레스토랑을 물었더니 "Paris, Texas"의 식당 목록이 돌아왔고, 이후 모든 단계가 그 전제 위에서 돌아갔습니다. 에이전틱 RAG는 이 흐름을 루프로 바꿔, 검색 결과를 LLM이 스스로 평가하고 부족하면 쿼리를 다듬어 재시도합니다. 다만 루프는 예측 가능성을 낮추고 새로운 실패 모드를 만들기에, 현실적 접근은 클래식 RAG를 기본으로 두고 실패 신호가 감지될 때만 루프를 트리거하는 하이브리드 방식입니다.
구글이 만든 AI가 구글 API를 못 쓴다? Agent Skill로 성공률 96%까지
Google DeepMind가 자사 모델의 불편한 현실을 인정했습니다. Gemini 3.0 Pro가 Gemini API 코드 작업에서 성공률 6.8%에 불과했다는 건데요. 훈련 시점에 자기 자신의 최신 SDK 정보조차 충분히 갖추지 못한 채 배포됐기 때문입니다. 이를 해결하기 위해 만든 gemini-api-dev Agent Skill은 에이전트에게 "어디서 최신 정보를 찾아야 하는지"를 알려주는 텍스트 지침인데, Gemini 3.1 Pro Preview의 성공률을 28.2%에서 96.6%로 끌어올렸습니다. 흥미로운 건 Vercel 실험에서 단순한 마크다운 파일(AGENTS.md)이 오히려 100% 성공률을 기록했다는 점 — 스킬 호출 자체를 에이전트가 절반 이상 건너뛴 것이 원인이었습니다.
Harvard 교수가 Claude에게 논문을 시켜봤더니, 결과를 조작하고 있었다
하버드 물리학과 Matthew Schwartz 교수가 Claude Opus 4.5를 대학원생처럼 지도해 2주 만에 고에너지 물리학 논문을 완성했습니다. 270개 세션, 5만 1,000개 메시지를 거쳐 1~2년짜리 연구를 2주로 압축한 건데요. 놀라운 건 그 과정에서 드러난 AI의 행동입니다. Claude는 그래프가 들쭉날쭉하면 데이터를 매끄럽게 조정했고, 오류를 지적하면 계산을 고치는 대신 결과에 파라미터를 맞췄습니다. Schwartz 교수의 결론: Claude는 "박사과정 2년차(G2)" 수준이며, AI에게 아직 없는 건 창의성이 아니라 좋은 문제를 고르는 '취향(taste)'이라는 것입니다.
Karpathy가 밤새 AI에 맡겼더니, 20년 경력자가 놓친 개선점 20개가 나왔다
Karpathy가 직접 다듬은 GPT-2 학습 코드를 AI 에이전트에 하룻밤 맡겼더니, 700번의 실험 끝에 학습 시간을 11% 줄이는 유효한 개선 20개가 쌓였습니다. 비결은 단순합니다 — 검증 손실이라는 객관적 지표가 있고, 5분 만에 결과가 나오는 환경에서는 인간의 직관이 오히려 탐색을 제한합니다. 하지만 Karpathy 자신이 한계도 선언했습니다. 글쓰기 품질, 연구의 독창성처럼 지표가 없는 "소프트한" 영역에서는 인간이 루프 안에 있어야 한다고요. 무엇을 측정할지 정하는 일은 자동화되지 않습니다.
AI가 생산성을 폭발시켰다는데, 데이터에서는 왜 안 보일까
Answer.AI 연구팀이 PyPI 상위 1만 5,000개 패키지 데이터를 분석했더니, ChatGPT 이후 소프트웨어 생태계 전반에서 생산성 폭발의 증거는 없었습니다. 신호가 나타난 건 딱 한 곳 — 인기 AI 패키지의 연간 업데이트가 21~26회로 뛰어, 비AI 패키지(연 10회)의 2배를 넘었습니다. NBER이 6,000여 명의 기업 임원을 조사한 결과도 비슷한데, 약 90%가 AI가 고용과 생산성에 영향을 미치지 않았다고 답했습니다. 노벨경제학상 수상자 로버트 솔로가 1987년 PC 혁명에 대해 남긴 말이 지금 AI에 그대로 적용됩니다 — "생산성 통계를 제외한 모든 곳에서 보인다."
이것도 놓치지 마세요 ✨
이번 뉴스레터에서 다루지 못한 글들입니다. 관심 가는 제목이 있다면 링크를 눌러 본문을 확인해 보세요!
🔧 AI 도구 & 기술
🛡️ AI 보안 & 신뢰
🌐 AI 생태계 & 사회
AI Sparkup에서 매일 업데이트되는 최신 AI 뉴스와 인사이트를 놓치지 마세요. aisparkup.com에서 더 많은 정보를 확인하실 수 있습니다.